Microservices Starter Kit v1.2
(Updated Jan 23, 2025)
Download the Microservice Checklist PDF!
The Microservice Checklist is now available as a simple one-sheet to hang up on your wall!
Microservice Checklist
The Microservice Checklist
To ensure these services behave and interact properly we must ensure certain best practices and approaches are in place. Running in a docker container exposed on port 80 is just one of the basic tenets of any service and there are many more for basic service design. This document is not intended to describe the architecture or tech stack of a service from the ground up. Instead it is designed to describe to a service author the things all services must/should do in order to properly live in the shared microservices ecosystem.
1. Service Naming
All services should follow the same naming convention and use a DNS name to be addressed. The name should be in the format:
[service name]-service.[environment].[domain].com
eg:
collection-core-service.dev.tiltwire.services
album-service.dev.tiltwire.services
artist-service.dev.tiltwire.services
It should be clear to the caller if the uri represents a REST service or a front end
application with the existence of the “-service” suffix on the service name. If the
uri represented a front end application named inventory it would be represented as such:
[application name].[environment].tiltwire.services
eg:
music.dev.tiltwire.services
The term “core” can be used to describe a service that is central to a specific domain and shared
across multiple domain bounded services.
2. Endpoint Naming
All endpoints should be resource based. Resources with more than one word should be hyphenated:
/albums
Further, collections and sub-collections should be designed in a descriptive and easy to read manner:
/artists/{artistId}/albums/{albumId}/songs/{songId}
This allows a consumer to:
- Get a list of all artists
- Get all albums for a specific artist
- Get all songs for a specific album
- Get a specific song for a specific album
https://artist-service.tiltwire.services/artists/{artistId}
https://album-service.tiltwire.services/albums/{albumId}
https://song-service.tiltwire.services/songs/{songId}
These endpoints will allow for the CRUD operations on each resource. However, it
does not specify the relationship between them: an artist owns an album which
owns a song. The following list better demonstrates the relationship and allows
for better management of the child objects:
https://artist-service.demo/artists/{artistId}
https://album-service.demo/albums/{albumId}
https://album-service.demo/artists/{artistId}/albums/{albumID}
https://song-service.demo/songs/{songId}
https://song-service.demo/albums/{albumId}/songs/{songId}
Now we can query album service to get all albums by a specific artist. Similarly, we can query the song service to
get all songs on a particular album.
3. REST
All services should follow the REST standards ( REST API URI Naming Conventions and Best Practices ) and as such all endpoints should be resource based and not action based (eg: employees instead of add-employee).
4. Standard Payload Format
All request and response payloads must be in JSON format with property names specified in camelCase. Example:
{
"firstName": "John",
"lastName": "Smith",
"address": {
"street": "21 King St.",
"city": "New York",
"state": "NY",
"zipCode": "10042"
},
"phoneNumbers": [
{
"type": "home",
"number": "212555-1234"
},
{
"type": "mobile",
"number": "6465551254"
}
]
}
5. Consistent Error Results
Errors should be handled using an appropriate HTTP Result Code as well as a simple payload body with more details. The simple body should be as follows:
{
"datetime": "2024-03-21",
"traceId": "",
"status": 500,
"title": "Internal Server Error",
"stackTrace": ""
}
6. Centralized Logging
By default, K8S logs are written to the console inside each pod when running inside
K8S. This is troublesome as it can require ssh access to the host in order to view
the logs. Further, logs are isolated from each other making tracing calls across
multiple services difficult and time consuming. The ELK stack solves this problem
for us. All services should write all logs to Logstash which makes them available
for searching/filtering in Kibana. This is a very powerful tool as it allows us to
filter by date/time range, service name, transactionId and other things in a convenient
and powerful UI.
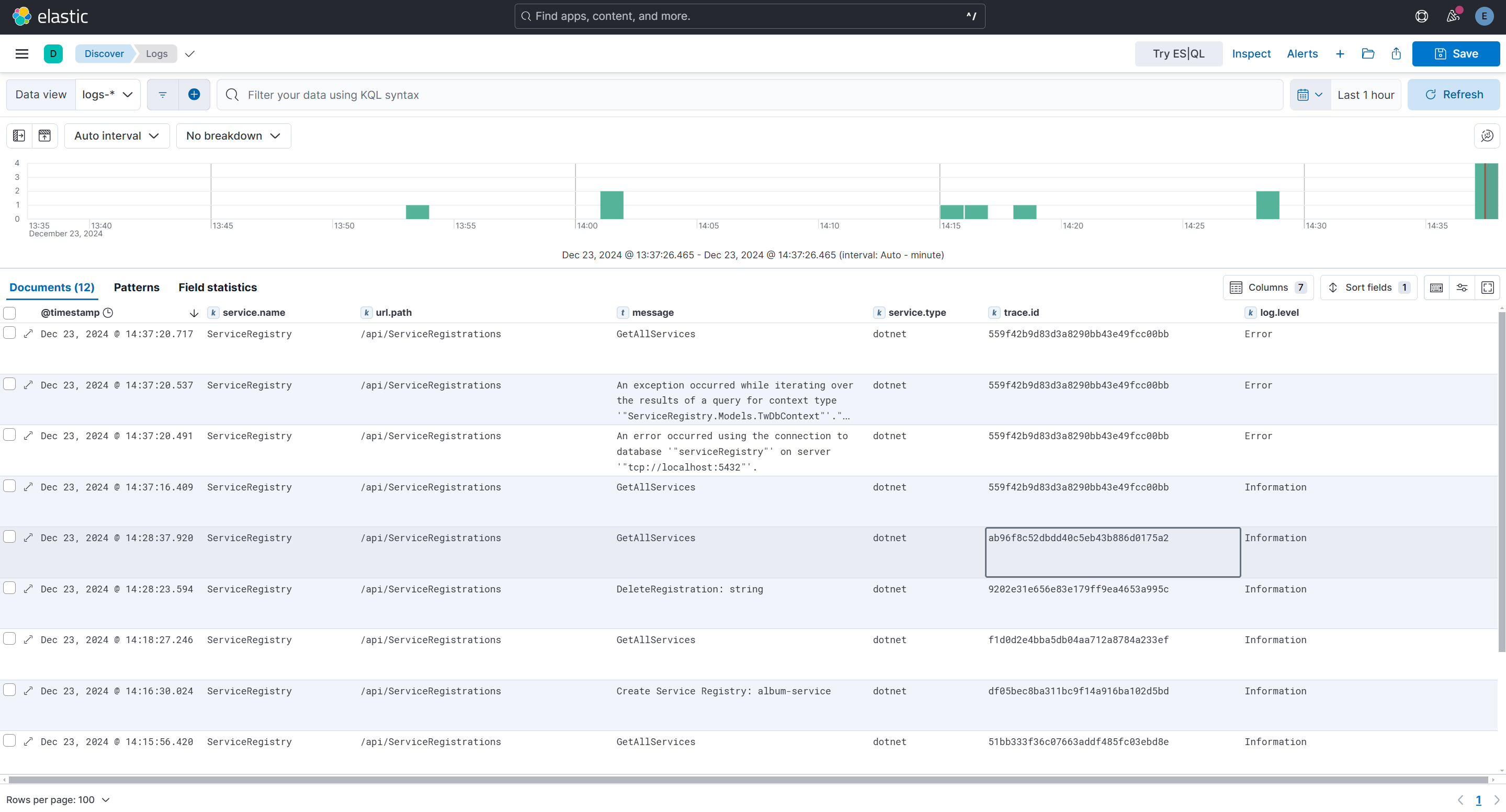
| Name | Description | Required |
|---|---|---|
| serviceName | The name of the service that generated the log entry. (eg: dealer-core-service). This should be the same name used in the Service Registry | Yes |
| message | The content of the message. This can be as complex as necessary including stack traces but at the very least should provide context to the action | Yes |
| level | The logging level (INFO, TRACE, WARNING, etc…) | Yes |
| type | Language of the service (eg: PHP, C#, JAVA, etc…) | Yes |
| traceId | the UUID of the transaction | Yes |
| targetServiceName | The name of the service being called. (eg: dealer-core-service). This should be the same name used in the Service Registry. | Optional |
| targetRequest | The request is being passed to the target service. This could contain the query string, body or both | Optional |
| targetResponse | The response returned from the target service. | Optional |
7. OpenApi (in NON Prod)
Swagger is an excellent middleware that exposes a webpage that allows developers to
fully interact with all endpoints exposed in a service. It also supports Authentication
so a JWT token can be provided on guarded calls. Most languages provide an implementation
of Swagger. Since Swagger pages provide a wealth of information that can be used for
nefarious reasons, it should be disabled in Production environments.
NOTE: The url for the swagger page should be:
https://<root service url>/swagger
eg: https://serviceregistry-service.dev.tiltwire.services/swagger
8. Service Discovery
Service Registry is a central location for service discovery. It prevents services and apps from having to hard code or make assumptions about the locations of dependent URIs. All service dependencies should be retrieved, at startup, from the Service Registry by calling on of the endpoints available. Services can be retrieved by name, domain or by passing a list of names to ensure a single http call.
9. Database Migrations
Over time we will be dealing with dozens of services, across multiple environments, each with its own release schedule. It is critical that we reduce any and all manual intervention required to get a service up and running. As such, all services should use a framework to enable automated database migrations which will handle creating all required schema and any data population/manipulation to make the service function as expected once deployed. Some examples are Entity Framework (C#) and Flyway (Java).
10. Health Endpoint
When a service is deployed to K8S, it uses a readiness probe to determine when the pod is available to retrieve traffic and the old one can be deleted. This process is critical to preventing 502/503 errors and ensures transparent releases. To accomplish this K8S will call the health endpoint of the pod expecting a 200 result. Once it receives a 200 result it will begin to route traffic to the pod. If it does NOT receive a 200 it will retry based on the retry config and eventually kill the pod and start a new one. The health endpoint should be named “healthz” and be available from the root.
eg: https://some-service.dev.tiltwire.services/healthz
11. Environment Variables
Since the general approach is to build the container once and then run it in multiple environments, we require an approach to configure the service across environments. Environment variables solve this problem for us nicely. When a container is deployed to K8S, a collection of environment variables are injected into the container. This allows the service/app to properly function in any environment we choose. Since most of our services are written in C#, it is a good idea to have a shared library that services can refer to in order to ease the burden of referring to environment variables. It is preferable to have all injected variables start with a common prefix to be able to easily identify them. The preferred prefix is “APP_”. Example: APP_ENVIRONMENT
12. Authentication & Authorization
Adopting an IDP (Identity Provider) is critical to securing the ecosystem. An IDP can secure general access as well as what actions can be performed via JWT tokens. The tokens can be used for Authentication and JWT Claims for Authorization. If at all possible use as few as possible (one is best) tokens across the ecosystem to reduce complexity and consumer demands. All calls to a service must provide a JWT token that can be validated for Authentication.
13. TraceId
In order to be able to better follow a flow when it crosses service boundaries we need a trace id. This trace Id is a UUID that is either read out of the trace-id http header OR generated if the header does not exist. Any service to service calls must include this header and pass a known/passed trace id through OR generate a new one to pass. It should also be logged so it can be used as a search field in Kibana.
14. Service Registry Auto Registration
In order to ensure a service is available in Service Registry in all environments that service runs in, it should perform an auto registration at startup. This is a simple POST to the Service Registry to provide information about the service including:
| Name | Description |
|---|---|
| serviceName | Name of the service |
| uri | Uri of the service |
| domain | Domain of the service |
| description | A short description of the service |
15. Accept-Language for Localization
When a service supports multiple languages it should use the Accept-Language header value specified by the consumer to determine which language to use in the response. It should follow the http specification.