Microservices Starter Kit v1.2
(Updated Jan 23, 2025)
Architecture Considerations
Introduction
The past 30 years of application development has seen many changes. From mainframe green screens (100% server based) to client/server (50% client/50% server) to early web development (100% server based but with colors and pictures!) to modern web development using client side frameworks such as Vue and Angular (50% client/50% server) we have shifted from back end processing to front end and back again. Much of this is a result of the ubiquitous nature of the internet, more powerful client hardware and the ability to exploit that power to run applications closer to the user. Many applications built in the past 10 years would fall into the “modern web development” category describing a rich client, either desktop or mobile app, and a server backend to persist data. Many of these systems are very large and would be considered monolithic due to the nature of a very large, single code base, and typically single deployable asset. Recently a new approach has emerged that seeks to create highly reusable, infinitely scalable while enabling development teams to quickly deliver application features free from restrictions due to previous architecture/language/framework decisions. As with anything there are pros and cons and this new flexibility does come with a cost. Let’s look at the pros and cons of each approach.
Monolith vs Distributed Architecture
I use the term “Distributed Architecture” vs “Distributed Services” to make the distinction of what it contains. Distributed services would be a collection of services that perform a specific purpose and are consumed by one or more applications. Distributed Architecture is the approach that allows these services, and applications to interoperate and communicate.
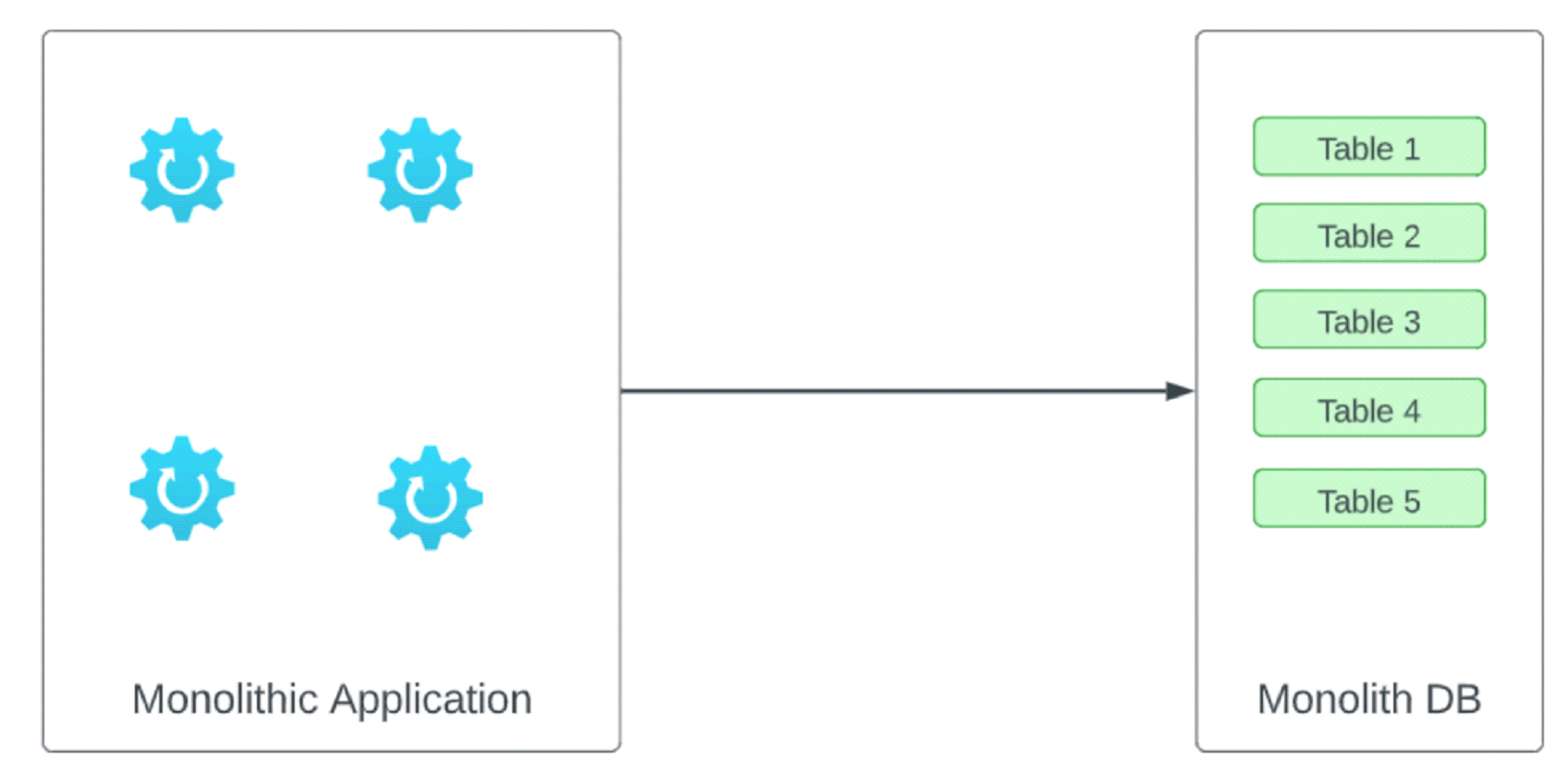
Figure 1 demonstrates a monolithic application that provides multiple features and uses a monolithic database. Monolithic applications benefit from a single build asset which makes them easy to deploy however they typically are very large code bases which can be difficult to manage. Once a language and architecture/framework is selected the monolith is typically married to that for life as it is very difficult to change. As time goes by they typically end up with sections of dead code, code entanglement, unnecessary complexity, multiple architectural approaches and code and library redundancy. Since these tend to be very large code bases, they can cause IDEs to become slow and cumbersome to work with and can take a long time to build. Many of these applications require large amounts of intimate knowledge to make simple changes and suffer from poor test coverage which makes changes costly and risky to implement. Further, as these systems age so does the technology and maintenance costs increase. Finally with team attrition it can be difficult to recruit talented developers willing to work on outdated frameworks/code.
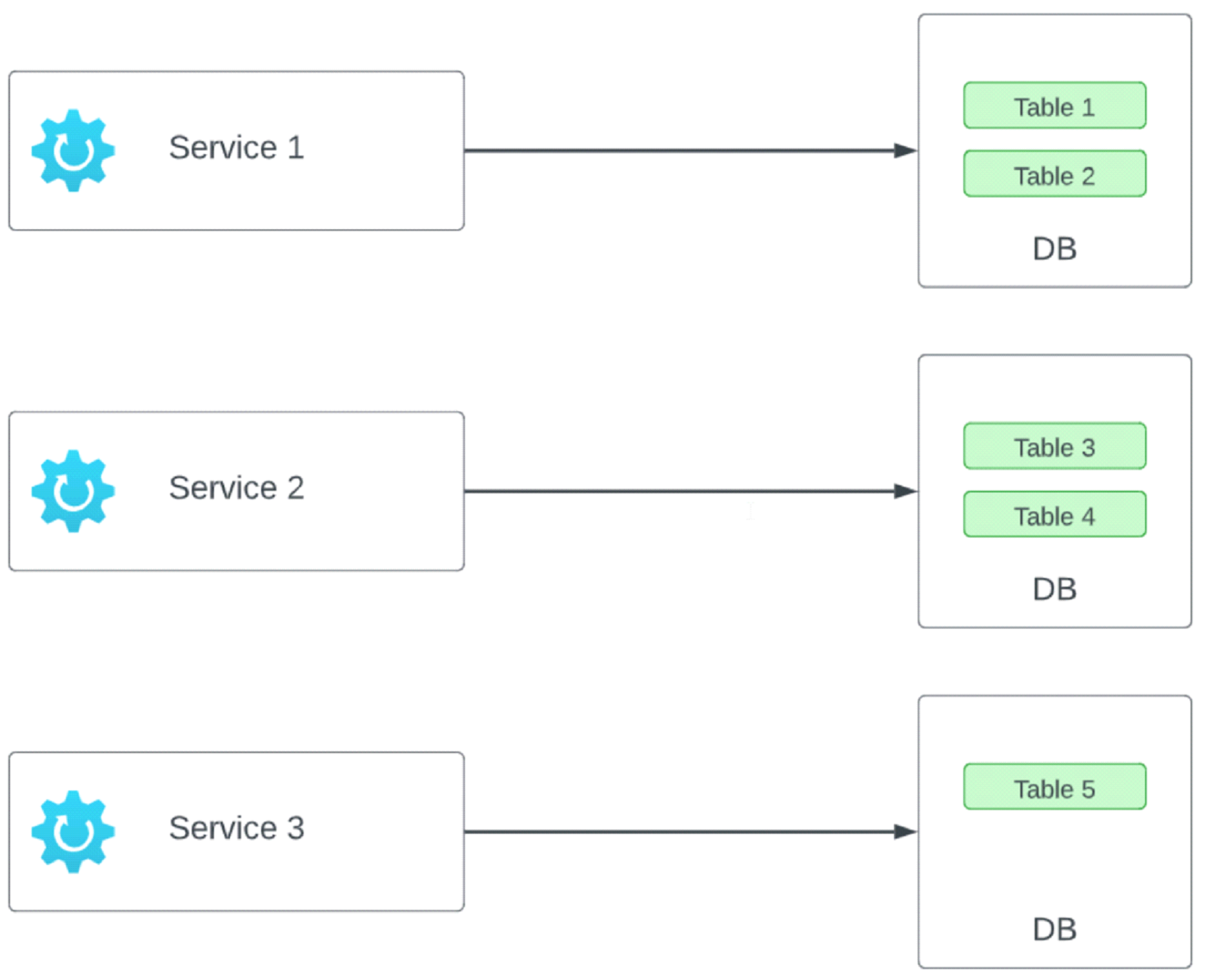
Figure 2 demonstrates the Distributed version of the monolithic application shown in Figure 1. Distributed architecture benefits from many atomic build assets, each in their own source repo and CI/CD pipelines. This allows them to be deployed independently of each other and in some cases greatly reduces the complexity of a single release. Further, we realize the benefit of making decisions based on what is best for the thing being created, free from decisions of the past. This can include the best language for the job, best persistence, etc.. We can also adopt new libraries/architectures/best practices. The atomic size of the pieces encourages future proofing as we build, allowing new services to benefit from modern best practices, languages and frameworks. These “things” can include microservices, front end applications written in client side frameworks like Vue or Angular, scheduled jobs and others. With all these benefits come many challenges. Managing multiple small things vs one large thing can be challenging and require a certain organizational discipline. Deployment becomes more challenging as a single monolithic deploy could be replaced with multiple deploys to achieve the same result. As a result DevOps plays a significant role in a distributed architecture. Fault tolerance, partial success and multi-service transactions are a major consideration as we now rely on disparate services to perform a single operation, where one or more of these steps could fail. Service design must be done in a more general way to accommodate future consumers. Versioning must be considered to ensure changes do not break existing consumers. The huge benefit to an organization is that each service/component can be considered a Leggo block that can be used in the construction of any new systems and re-engineering of existing systems As such an organizational paradigm shift in thinking, approach and discipline is required to properly implement and support a distributed service architecture as the impact will be felt in more than just the technology department. The customer support department must be aware of all the moving pieces and their impact on the operation of the entire system. Infrastructure support must be aware of all the moving pieces in order to properly monitor and ensure system availability. Fortunately, there are many tools, frameworks and platforms widely available that help address many of these challenges and have allowed the industry to embrace distributed architectures.
Considerations
There are many considerations with any application development approach. Distributed architecture does provide some unique challenges given it’s distributed approach. Let’s review some of these.
Language Agnostic LA
One of the benefits is the ability to make decisions on a unit by unit basis, free from the decisions of the past. Whether the unit is a microservice or client side application we should be free to make decisions based on current industry best practices, tools and frameworks. Traditionally, this amount of freedom would just create a massive burden on the infrastructure support team given it could require Microsoft stack, java stack, php stack, different database technologies and cloud vendors.
Many Moving Parts MMP
Instead of a single deployable asset, we now have to manage many. Dozens to hundreds in some cases. This puts extra emphasis on deploy strategy, quality and integration validation. Further, we now have many things to monitor health, resource usage and logs. Finally, we want to realize the value of smaller assets by being able to scale them independently to meet their individual demands.
Standardized Service Communication SSC
Given we anticipate having many things that will accept consumers and consume other things we must standardize on the communication protocols/approach each will support. This establishes the communication language each of the things will understand regardless of implementation details.
Enterprise Events EE
Although part of a standardized service communication, enterprise events can serve a higher purpose. Asynchronous inter-service communication can become an invaluable mechanism to super-power a distributed platform. Further, it can quickly integrate legacy and monolithic apps into the platform by simply subscribing to or publishing enterprise events that other components can interact with.
Service Discovery SD
In most cases applications will depend on a microservice. Further, a microservice may depend on one or more other microservices. Given we have many per environment and will have multiple environments, this demands a mechanism in order to ease a consumer’s demand for knowledge of a service or resource it depends on. Changes to a service must never break a consumer that consumes it. In some cases it is difficult or impossible to anticipate what is consuming a service. There must be an approach to allow multiple endpoints over time that serve old and new consumers of the same type of data.
Centralized Logging CL
With many components running in an environment, and certain application processes crossing service boundaries it becomes critical to have a central way to view logs and trace requests. Switching between the log of each unit can be done but is extremely inefficient and not recommended.
Quality Assurance Automation QAA
With so many components being deployed on independent schedules, free of any sprint boundaries or release schedules, it becomes much more important to ensure the quality of these components. Test automation is the perfect approach for this and can/should be run after every single component release.
Authentication & Authorization AA
Authentication is proving a user is who they say they are to an application. Authorization is when an application ensures a user can only perform the operations they have been predefined to have access to perform. In a distributed architecture this becomes tricky as we don’t want each component author to implement their own approach. It must be applied consistently across the platform.
No Manual Intervention NMA
With so many components being released it is absolutely critical that they deploy automatically and set up what they need to run. This means there should be no hand holding to get a service running in a new environment other than basic resource provisioning (such as a db container) and environment variables.
Tech Demands
We have identified many of the challenges faced when moving towards a distributed architecture. Let’s now look at the technology solutions that will help solve or manage these challenges.
Containerization
Containerization has gained massive popularity over the past decade and for good reason. Docker has emerged as one of the leading products to support development of applications running inside containers. Containers allow us to use a virtual file system where we can install whatever we choose (.net runtime, Java, nginx, etc…) onto whatever base image (Alpine Linux, Ubuntu, etc…) we need. The huge benefit of a container is once it’s built and tested it can be shipped and run anywhere. The contents of the container is inconsequential to the user as the container simply contains a port to communicate with it. This solves a massive problem for distributed architecture as we can build one container that contains a PHP service, another container that contains a Java service , a third that runs a C# service and finally a container that runs a Vue application. All the consumer of these containers needs to know is the port and mechanism by which to communicate with the contents.
Solution: Docker remains the only real choice at the moment and by far the most adopted containerization tool in the industry. The developers can use it on their desktops and it can be used on our build agents to build containers that are CRI (Container Runtime Interface) compliant. This allows them to run on other container runtime engines such as containerd.
Solves: LANMA
Container Orchestration
Container orchestration comes in many flavors. Docker has its own flavor in Docker Swarm which can be used for light applications. Kubernetes (K8S) has emerged as the industry heavyweight and was built by Google. It is currently viewed as the de facto container orchestration platform. Cloud vendors also have their own flavors such as ECS and Fargate which were both purpose built by Amazon to run in AWS. K8S, ECS and Fargate (which is really k8s on “virtual” EC2 instances) provide similar functionality and are designed to serve a host to multiple services/applications running on a common platform. We can remove Fargate from consideration as it is very expensive and slow when compared with ECS and EKS (K8S). Comparing ECS and EKS finds that both provide similar functionality at an almost identical price point. K8S is open source and has a massive community for support. It runs on prem on bare metal, in all cloud vendors (GCP, AWS and Amazon all support K8S) or on a windows desktop (Docker includes a running version of K8S that uses minikube).
Solution: We have an existing investment in both ECS and K8s (AKS in Azure). We have ~20 services running in 4 environments across 2 clusters in AKS (80 total) and ~13 services and 2 monoliths running in 2 environments across 2 clusters in ECS (30 total). Regardless of the choice made, a migration effort is required to standardize all services onto a single orchestration platform. Given we have in house knowledge on ECS and not on K8S, ECS will provide a quicker path to realizing the platform vision. As such, ECS is the preferred approach.
Solves: MMPNMA
REST
REST (Representational State Transfer) borrows heavily from the http protocol definition by demanding that all endpoints be resources based, http verbs (GET, POST, PUT, DELETE, PATCH) are used to interact with them and to determine the nature of interaction and that http result codes are returned (200 for Created, 404 for not found, etc…) REST is a widely supported approach for building web services. GraphQL is an alternate approach built and supported by Facebook. The implementation must be more generic and is more geared to shaping and filtering the response. REST services typically conform to OpenAPI standards which provide excellent documentation autogenerated for free as well as a UI to interact with the service.
Solution: For most applications REST is the best and simplest solution.
Solves: LAMMPSSCAA
Enterprise Events
Events and queues often get conflated in today’s tech speak. Message queues have been around for 30 years and are typically write once/read once meaning once a message is read it’s gone. This is fine if you have an asynchronous work queue and need multiple workers to grind through it. In a distributed architecture there are other demands, such as the ability to raise an event that any component on the platform can read and respond to, at any time in its lifecycle. This becomes an important distinction and an incredibly important feature when we consider we could have a user perform an action like creating a user, raise a UserCreatedEvent and then multiple services could take action based on that single event! LinkedIn was the first to identify this need/benefit and built Kafka as a result. It is really the only event streaming framework available that has been industry hardened and tested. It runs in a cluster, provides guaranteed event delivery, consumer groups for multiple consumers of the same events to ensure single delivery as well as many other features. All cloud vendors provide Kafka as a supported resource.
Solution: Kafka allows us to generate one event and read that event multiple times from many different consumers at widely different times. For example a new service could start processing events from years ago if required.
Solves: SSCEE
Centralized Logging
The ability to store logs in a central location and query them is critical to any distributed architecture. Many cloud vendors have a tool to do so (AppInsights in Azure, CloudWatch in AWS, etc…) but most are of poor quality and were built for resource logging, not application level logging. Fortunately, Elasticsearch was released ~10 years ago and has since become the definitive platform for application logging and insight. Using a combination of the ELK stack (Elastic, Logstash and Kibana) becomes the perfect toolset to capture, store and visualize/query logs.
Solution: ELK. Given we already have an investment in Elasticsearch and it is extremely well suited to the job it seems like the prudent choice. Logstash, file beats and Kibana will need to be added to complete the full “ELK” stack for a very robust logging platform.
Solves: LAMMPSSCCLNMA
Authentication & Authorization
A solid, yet easy to use and manage security framework is critical to securing components in a distributed architecture. The ability to add users, grant them specific claims/rights and then retrieve a JWT (Java Web Tokens) is paramount. It is best practice that all microservices require a JWT token in the Authorization header of each and every request. This token is validated upon each request and a 401 returned if the token is invalid. Further, the claims inside the token can be used by each service/application to provide authorization rules to control access to specific operations. OAuth has emerged as an extremely popular security protocol and implementations of it are used by all major online retailers and websites. All cloud providers have their own implementation (Cognito for AWS, Azure AD/ADB2C for Azure) and there are open source solutions such as keycloak that all provide similar functionality.
Solution: Keycloak is a free, cloud agnostic solution that provides OAuth support and features that support our organizational needs now and for the foreseeable future.
Solves: LAMMPSSCAANMA
Persistence Management
Most services will require some form of persistence whether temporal or permanent. In either case it should be incumbent on the service to manage its schema, seed its own data and perform any data migration required. This should happen automatically at service startup. Most languages have their own implementation of this: Entity Framework for C#, Flyway Migrations for Java and Symfony’s Doctrine for PHP for example.
Solution: The service must use the appropriate library to support db migrations.
Solves: LAMMPNMA
CI/CD
Due to the ever growing nature of the number of components in a distributed architecture, it is imperative to start with an automated approach to build and release. Fortunately there are many good CI/CD tools available today. These tools allow code and containers to be built and pushed on check in as well as kicking off releases to required environments. At a minimum a CI/CD pipeline must exist for each component which will build the code, package it in a container, push the container to a container registry, deploy that container to a container orchestration platform and then run integration tests to ensure the correct version is deployed and that it is performing as expected. Currently we have an investment in Azure DevOps as well as AWS CodeDeploy. Github actions are also an option. The challenge with selecting a winner here is that it is not an apples to apples comparison. CodeDeploy is a dedicated ci/cd tool. Github actions is an extension to github to support ci/cd. DevOps is a complete SDLC tool featuring work item tracking, planning, source control, ci/cd, asset management and test management including full traceability.
Solution: Azure DevOps is a great, low cost option.
Solves: LAMMPQAANMA
Service Discovery and Registration
Applications and services will undoubtedly have dependencies on one or more services. To reduce entanglement it is important that these dependencies remain loosely coupled. However this presents some challenges when discovering dependencies, especially when the same container can be run in multiple environments. As such, hard coding references is not an option and environment variables can become unwieldy. A better solution is a service that provides the ability for a component to query it to dynamically retrieve the location (URL) of its dependencies based on the environment it is running in. Further, the same service should allow a component to self register so it is available for discovery. This is not a complex process and can be accomplished with a small handwritten service with a simple schema and a controller. There are off the shelf products that also serve this need, and more, such as consul.io.
Solution: The use case is very simple and fairly static and a custom service registry service already exists. It would be much quicker to deploy the custom service than learning a new tool that may introduce unnecessary complexity. As such, the custom Service Registry is the best solution.
Solves: LAMMPNMA
Putting it together
Now that we’ve identified the technology to help solve the challenges, let’s examine how it fits together. Figure 3 demonstrates multiple concepts: synchronous and asynchronous service consumption, service to monolith synchronous communication, and expanding the functionality of a monolith via enterprise events.
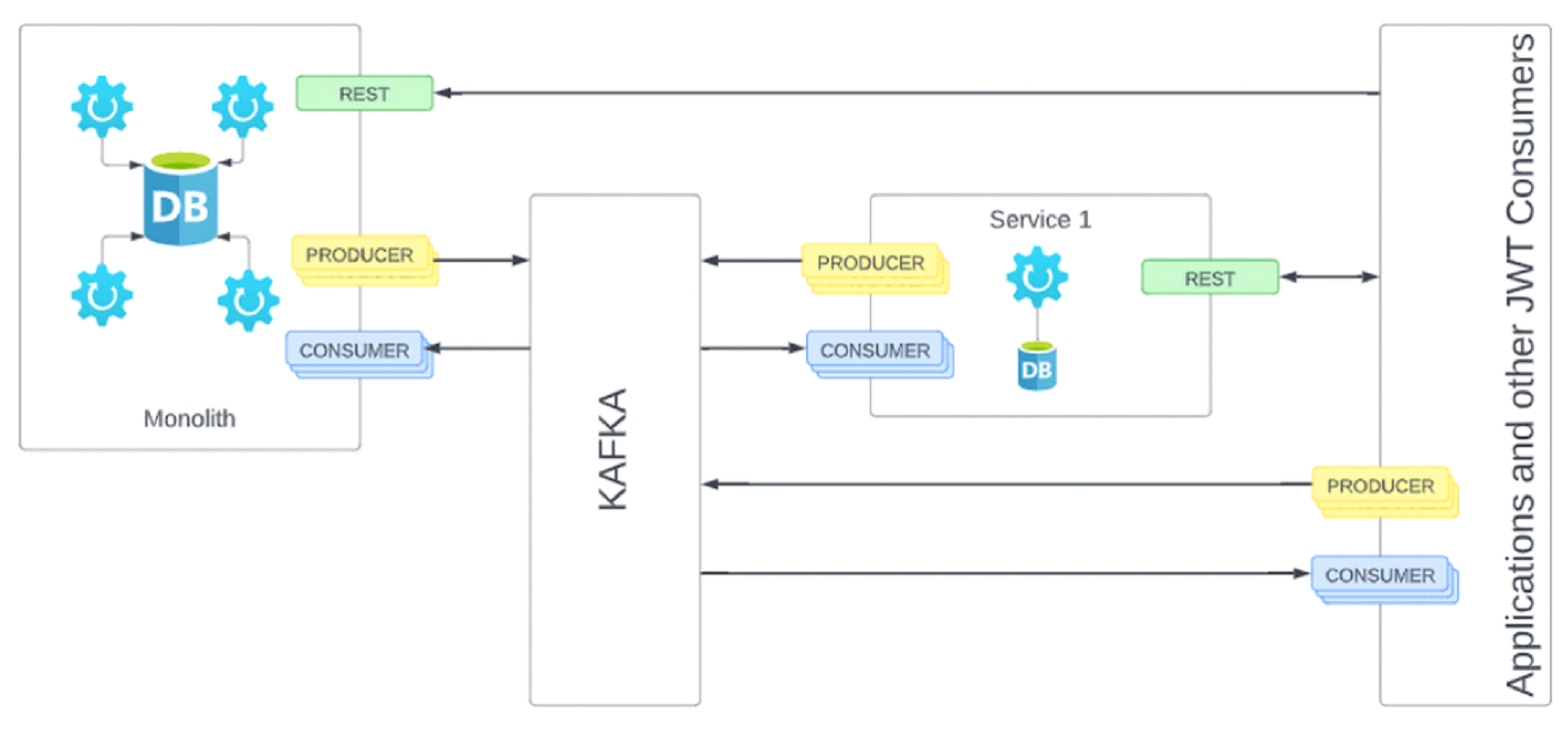
Front End applications call services via synchronous REST/HTTP calls. Services call other services via synchronous REST/HTTP calls. Services can interact with other components via asynchronous events via Kafka. Further, Monoliths can participate or be expanded via the use of asynchronous events via Kafka. By producing events based on user or system actions services can respond and expand functionality across the platform. Inversely, a monolith consuming events can respond to new events generated by services/applications elsewhere on the platform. This allows the flexibility to tactically migrate monolithic applications to a distributed architecture over a period of time.
Process
Now that we’ve talked about architecture and the technologies that will form our technology stack, we must discuss the process by which the technology team can work to be most efficient. There are three main roles that must be present in order for things to run smoothly: Developer , DevOps and Test Automation.
Developer Role
The developer is responsible for following the architecture as described, following best practices for communication, anticipating future service consumption and ultimately determining the base requirements for a component. This is not much different than a typical approach where a developer will start a project, make decisions around language, architecture, frameworks, etc… except in this case containerization and service communication must be considered. On top of writing the code and unit tests to meet the spec, the developer is now also responsible for determining the base container image required to properly run the component. Any dependencies must also be considered here which requires the creation of a Dockerfile to build and test a container prior to code promotion. Finally any new resource demands must be communicated out to other teams. This is critical to ensure proper container operation down stream. Also, note that since the developer is creating the container it is not required to have any downstream knowledge of the orchestration framework which the container will ultimately run on top of. In fact, the developer should be completely agnostic of the specifics here as they can change without developer knowledge or engagement.
DevOps Role
Once a code PR has been approved and merged, DevOps takes over by building and maintaining the CI/CD pipelines required to build and deploy the component. Further, DevOps is responsible for standing up any infrastructure required by a component. It is not the responsibility of the DevOps team to manage code or create images but they can oversee and collaborate on the selection of base images to ensure consistency across the platform.
Test Automation Role
Once code has been deployed to a dev or test environment, a battery of automated tests should be run against that code. These tests typically consist of integration tests and e2e tests. Integration tests would simulate http calls to a service endpoint to test positive and negative outcomes and verify proper payload, security and http result codes. E2E tests would act like a robot interacting with a front end application to simulate user interactions to ensure functionality works as expected. It is absolutely critical that this step takes place after every release in an automated fashion and that these tests are continually kept up to date and expanded over time. It is the responsibility of test automation to create these tests as part of the sprint work. These should be built in collaboration with the team based on work defining any creation of end points or from end applications.
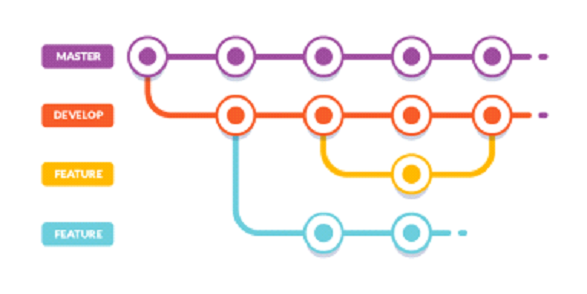
Branching Strategy
A solid branching strategy is always required for consistency and success and is no different here. There are, however, some distinctions here that cause some changes in thinking when it comes to branching. Over the past number of years, many git teams have embraced Gitflow as a branching strategy. Gitflow is a good approach when dealing with more monolithic releases with a slower cadence. It also demands multiple branches for each “environment” which is contrary to the “Build Once, Ship Many” approach of a containerized strategy. As such, Gitflow does not really fit. The good news is a very simplified branch strategy fits very nicely here. Let’s review our process. A developer builds a feature and wants to deploy it. Since we only build the container once it’s greatly simplified by having a single “release” branch (let’s call it develop) and feature branches under that. A developer working on a new feature would create a feature branch off the develop branch, do their work and then create a PR to merge back to the develop branch. Once that PR is approved and the code is merged to develop the CI/CD pipelines built by DevOps would kick off to build and deploy the container and then run the automation tests built by test automation.
Deployment Plan
Now that we have determined the architecture, tech stack, infrastructure and process we can formulate a plan to implement across the technology department.
Infrastructure Provisioning
Before we can truly begin to sprint with component creation we need all the required infrastructure provisioned and configured. Figure 4 shows the action items required based on the decisions above.
The Template Service
In order to ensure success across all teams, it is useful to have a working example of a service that the team can use to learn from. This template service would include implementation of all items described in the Microservice Requirements document. This forms the checklist of base features all services should provide.
Training
As with the introduction of any changes, it is important that training is provided to the team in order for them to be successful. Despite the number of changes outlined in this document, there are actually very few major changes to each role. The following table describes the anticipated items and roles involved.
| Technology | Role | Notes |
|---|---|---|
| Docker | Developer | This should include basic operation of docker command line to manage images as well as Dockerfile settings |
| Kafka | Developer | Kafka Producer/Consumer Developer This will cover simply producing and consuming events as well as basic Terminology |
| Kafka Config | DevOps | This will cover basic terminology, creating and managing topics and basic cluster management |
| Auth0 | Developer, DevOps | This will cover basic JWT validation and claims and dashboard for user management |
| ELK | Developer, DevOps | This will cover basic Kibana usage for log querying and initial logstash setup |
Next Steps
A technology roadmap will be created to document all high level tasks required including their estimated length and predecessors. This roadmap along with this document will be shared and reviewed with the Executive Team and the SDMs. Once approved it will be shared with the broader team and information sessions be scheduled to present and address questions/concerns.